Delight your customers
with intelligent conversations.
At scale.|Globally.|Securely.



Trusted by the most disruptive companies on the planet
















Build customer relationships over every possible channel











Supercharge your platform with CPaaS X
Maximize operational efficiency, drive innovation and unleash growth potential.

Be up and running in no time
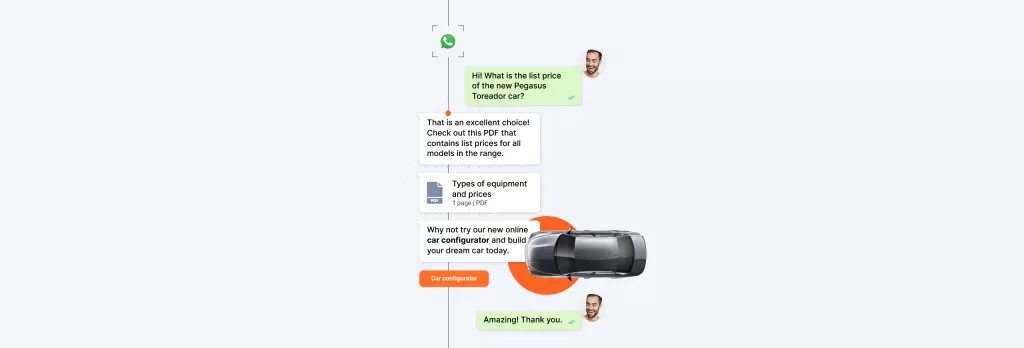
Build the experiences your customers want with our flexible API stack. Integrate their favorite channels with your business workflow to elevate their customer journey.
[INFOBIP AI HUB]
Build AI driven customer experiences. No coding required
- Acquire, grow and retain customers with Infobip’s conversational AI platform
- Build end-to-end customer journeys powered by AI
- Low-code, no-code or AI generated solutions built with Infobip AI Hub













The experts have spoken- Infobip is the CPaaS leader your business needs

Infobip is named a Leader in 2023 Gartner Magic Quadrant for CPaaS
We are proud to announce that Infobip has been named as a Leader in the 2023 Gartner Magic Quadrant for Communications Platform as a Service (CPaaS).
Read report
data centers across the globe data centers across the globe
global operator connections global operator connections
direct operator connections direct operator connections


Harness over 15 years of experience with the world’s most connected platform
With industry-leading expertise, you can deliver superb customer experience through our global network.
450 billion+ interactions per year
Achieve the highest delivery rates and scale your messages as you grow on our secure platform.
9,700+ global connections
And 800+ direct operator connections to facilitate reliable messaging and use cases anywhere in the world.
40+ data centers
Our worldwide data centers help you keep operations running smoothly and efficiently.
Highest standards of compliance
Send compliant messages anywhere in the world and in line with local regulations.
75+ offices on 6 continents
Global experience and local presence provides best-in-class service and solutions.
24/7 support
Always-on support and network monitoring available with expert service.
Together
we can transform communication
for your business
Grow your startup on the most reliable communication platform
Conquer new heights and achieve your goals with boosted engagement, scalability and wider reach with Infobip support.

Knowledge base – the Infobip library
Explore a wide range of materials to help you grow your business. Learn more about our latest updates, how to boost customer engagement, and best-practice guides to help you succeed.

Messaging Trends 2024
Discover the latest trends in business communication to help you become a conversational experience leader.


Get the latest insights and tips to elevate your business
By subscribing, you consent to receive email marketing communications from INFOBIP. You have the right to withdraw your consent at any time using the unsubscribe link provided in all INFOBIP’s email communications. For more information please read our Privacy Notice
