A success story using the Data-Driven Test Design Pattern in a brand new project.
When you are a tester and you are working on a brand-new project, I think we all like the idea of creating a fully automated test framework that can save us time in the future that we could use on learning new things, continue working on other requirements/stories or just on getting more coffee.
But in the real life we cannot always get rid of the manual test cases and besides that, creating automated test cases for a brand-new project following agile methodology can be sometimes a little overwhelming because the effort required to develop all the required test scripts is huge besides of the constant changes during every sprint and the manual test that still required to check the code stability.
Sometimes when you think you are done with one script, there is suddenly a new story in which the user needs a new field and this single field means modifying several test/test scripts.
My team and I are currently working on a constantly evolving brand-new project using agile methodology, so we had the necessity to create automated test scripts from scratch. We also wanted to find a better way to design them in a manner that if there are changes in the user stories, it doesn’t mean a full rework of the test scripts we already have.
Enter Data-Driven Test design
So how are we using the Data-Driven Test design work? Basically, we have our test data file, which is used as input for our test script. The test script runs all the actions/steps specified in the code using a piece of data from our data input file (it can be a row or a payload). Then it gets the actual result and compares it with the expected result. Once the comparison is done then it continues with the following data input from the file (row/payload).
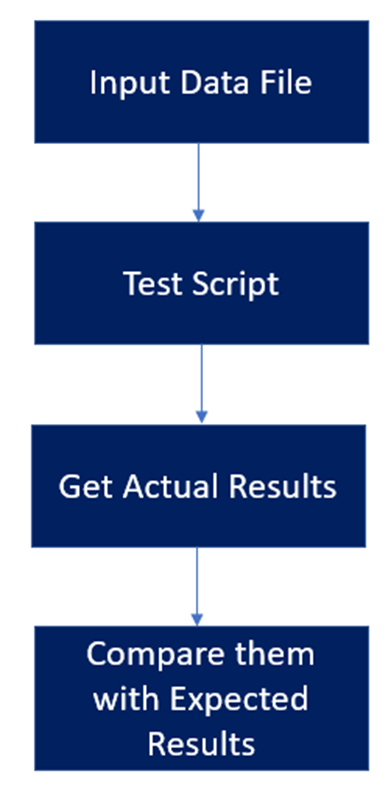
Some of the advantages we have found by following this pattern are:
- You can have more test coverage because while you are creating the data file you will have a better visualization of what have you already included and this will help you to identify if you are missing any test scenario.
- Scripts and functions can be reused in different tests and also be combined with multiple data files which give us a wide variety of test scenarios with fewer test scripts.
- Test scripts will run faster because most of the time with one single test you can cover positive and negative scenarios by just changing the expected result in our data file.
- Maintenance of our test scripts is easier, because if we are using one script which is testing both positive and negative test cases and there is a story in the future that implies that a field is no longer required, instead of making the changes in several scripts we only change one script and remove the field from the data file.
- The data setup required for the test execution can be also included in your data file and created inside your test script.
- And the more important reason for us is that there is no hardcoded data in your test scripts since you have the test data in a separate file. Changes to the scripts do not affect test data and vice versa.
Some general recommendations when creating the data file that has worked for us:
- The easiest way to visualize your data file, if you don’t know where to start, is every row/payload from your input data file will be mapped to a test case. You can add a row/payload with the data required for every test case that you will usually create. So, if you have one test script that is using a CSV file with 30 rows you will be testing 30 test combinations with a single script.
- Add every element/attribute/field as a parameter, so you can use the same data file for several test scenarios.
- Use element/attribute/field names related to the parameter you are going to replace so everyone who is checking your script understands it.
- In the case of API testing, if you have a field that is an array, add a field for every element you will add to the array including comas, so you are not forced to always enter the same array length.
- In the case of API testing, if you want to cover scenarios like validating the response code
404or checking theAuthorizationheader, you can add an URL field so you can test the response code404and a field withAuthorizationso you can test as many combinations as possible. - Use a field to describe your test scope, so you don’t forget what that payload or line was for.
- Add a field with the expected result. It can be a response code if you are testing an API or the text of a message if you are testing UI. If you do so, you can have both positive and negative tests in the same data file.
Currently, in our project, we are creating test scripts for:
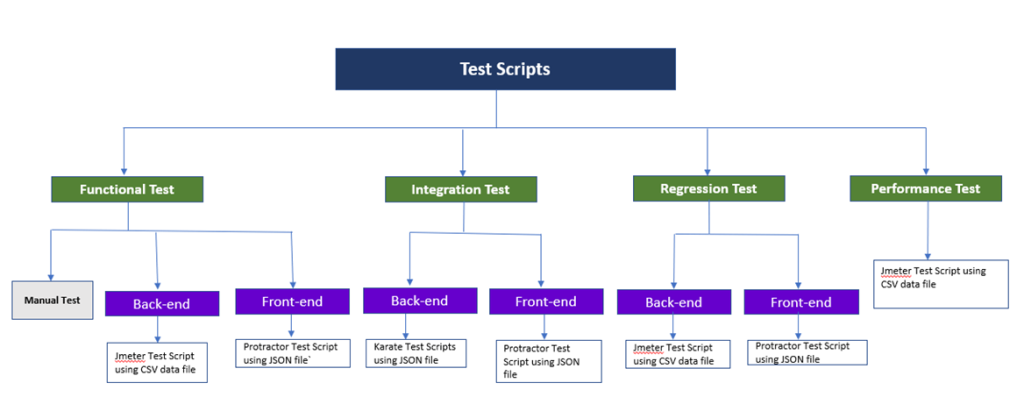
- The first try was using Jmeter (which we are using for API Testing and the Performance test). We started using it for REST API testing because there is a lot of documentation on how to use it, it is simple to use, easy to learn and it has all these “plugin controllers” that can be used to create your script. So, by using the CSV controller you can create a script using parameters and with a single script test positive and negative test in most cases. The only cons that we found were that if your payload is big is not that easy to visualize your CSV data file and you need a tool to separate the field by columns because if you try to use a regular text editor it can become a nightmare (and sometimes even with the columns you have to scroll your window). I also use a column for the test scope, so you can remember in the future what was the intention of that test.
- Since our brand-new project also has a UI and is developed in Angular then we started reviewing Protractor which was designed especially for angular and uses Webdriver and we were already familiar with Selenium. I created some test scripts and the transition from Selenium to Protractor was smooth and it works very nicely. I then started designing our test using a JSON file as our data input adding all the required fields for our test scripts and also a field for the test scope so we don’t forget what is the test intention of the payload (Recommendation when using a protractor to make your scripts easier to maintain separate your page object from your spec, and create a helper file that contains all the functions required to your script to run like click, add text into a text field, function to read the data file, etc.)
- In my experience, I like using JSON files rather than CSV files as data files, at least for me it is easier to read, and it looks cleaner and more organized.
- For all these reasons, I wanted to try another tool to create REST API test scripts using JSON files so last year I attended the automation Guild and there was a conference about Inuit Karate, which is kind of new, it uses Gherkins syntax, so it is not hard to learn, and I wanted to give it a try. I started creating integration tests and I like it because with the JSON file my data file looks clean and with the Gherkins syntax, the code is easier to understand.
- Besides the already mentioned tools, we have also created some other tools based on a data-driven test design pattern. We have some Python and Java script, for example, one to analyze the test results based on a CSV file and another to create JWT tokens based on a JSON file.
So, I already mention some of the advantages found following the Data-Driven Test design.
Is there any disadvantage from my point of view? Yes, when you have a field that is an array you must specify it in your data file and your array length will always be the same. Also creating the data file is not always the activity I enjoy the most especially in a CSV file, because since you are having all the test scenarios in files it is one of the more time-consuming activities when you are creating your scripts, the good news about it is that you only have to create the whole file one time and most of the times if any modification is required it is a minor modification.
Is there any way to mitigate this? Yes, we are trying to mitigate this by creating a test script that will create the test data for us and will solve the array issue too. We are not quite there yet, but hopefully, we will make it work, and the time we spend creating tests will reduce and our entire process will be more efficient.
Taking into consideration all pros and cons mentioned above: Data-Driven Testing was a good choice for our use case, we were able to move forward faster and made our lives easier. One of the perks of DDT is that, once a module has been fully automated, adding more test cases is just a matter of adding test data, very minimal changes are required for test scripts code 90% of the time.
So what’s next for us? We are working on creating a script that will help us to create the test data we need, instead of creating the data manually.


