






What is a large language model (LLM)?
Large language models (LLMs) are artificial intelligence (AI) systems trained on massive amounts of text data to understand, generate, translate, and predict human language.
These machine learning models work by analyzing patterns and relationships between words and phrases, much like how the human brain processes language.
Large language models can be likened to LEGO bricks in a way that makes the complex concept of technology more relatable to those outside the industry.
Imagine LEGO bricks as the building blocks of a vast, intricate structure, where each brick represents a piece of knowledge or language understanding. Similarly, large language models are like digital LEGO bricks, but instead of physical pieces, they are virtual components that understand and generate human-like text.
Building complexity
LEGO bricks can be combined in countless ways to create diverse structures. Similarly, with their vast knowledge base, large language models can be configured and combined to understand and generate a wide variety of textual content.
Versatility
Just as LEGO bricks come in different shapes and sizes to accommodate various structures, large language models are versatile in handling a broad spectrum of language tasks, from answering questions to generating creative content.
Interconnected knowledge
LEGO structures often have interconnected pieces, forming a cohesive whole. Similarly, large language models understand the connections between words, phrases, and concepts, allowing them to generate coherent and contextually relevant text.
Learning and adapting
LEGO creations can evolve as more bricks are added or rearranged. Large language models continually learn and adapt, getting better at understanding and generating text over time as they are exposed to more information.
Ease of use
LEGO bricks are designed to be user-friendly, allowing individuals of all ages to create. In a similar manner, large language models aim to simplify interactions with technology by understanding natural language, making it accessible to a broader audience.
Creativity and innovation
LEGO has fueled creativity and innovation in construction and design. Likewise, large language models drive creativity in content generation, enabling applications such as writing, translation, and problem-solving.
Potential for limitless applications
As LEGO constructions can vary from simple to highly complex, large language models offer various applications, from basic language understanding to advanced tasks like coding assistance or even generating entire articles.
By comparing large language models to LEGO bricks, the idea is to demystify the technology and showcase its adaptability, versatility, and potential for creative applications in everyday tasks. Much like building with LEGO bricks, interacting with large language models becomes a user-friendly and engaging experience, opening up new possibilities for communication and problem-solving.
How do LLMs work?
Large language models are neural networks trained on vast amounts of text data. These models learn the structure and nuances of human language by analyzing patterns and relationships between words and phrases. Attention mechanisms play a vital role in this process, allowing the models to focus on different parts of the input data selectively.
How are large language models trained?
Training a large language model involves feeding it extensive amounts of text data, allowing it to learn the patterns and structures of human language. The primary focus is on pre-trained models, which have been trained using unsupervised techniques on vast datasets.
Fine-tuning is the next step in the process, where the pre-trained model is tailored to specific tasks, such as text classification, sentiment analysis, or translation, by training it on smaller, domain-specific datasets.
What are the different types of large language models?
There are several types of large language models, each designed with a specific purpose and number of parameters:
- Zero-shot models: These are large, generalized models trained on a broad corpus of data, allowing them to provide reasonably accurate results for general use cases without additional training. A prime example of a zero-shot model is GPT-3, which can perform various tasks out of the box.
- Fine-tuned or domain-specific models: By further training a zero-shot model like GPT-3 on specific domain data, developers can create fine-tuned or domain-specific models that excel in particular areas. For instance, OpenAI Codex is a domain-specific LLM based on GPT-3 specializing in programming and code generation.
- Language representation models: These models focus on capturing and representing the intricacies of language. Google’s BERT (Bidirectional Encoder Representations from Transformers) is a prominent example of a language representation model that utilizes deep learning and transformer architectures to excel in natural language processing (NLP) tasks.
- Multimodal models: While early LLMs were primarily designed to handle text data, recent advancements have led to the development of multimodal models that can process text and images. GPT-4, the successor to GPT-3, is an example of a multimodal model that can understand and generate content across multiple modalities.
What are LLMs used for?
LLMs have an incredibly diverse set of applications across various industries and fields. Here’s a breakdown of some of the most common and exciting use cases:
Conversational AI and chatbots
- Enhanced customer service: LLMs power chatbots that answer questions resolve issues, and engage with customers 24/7, improving support and freeing human agents.
- Virtual assistants: LLMs drive voice assistants like Alexa and Siri, enabling them to understand complex commands, provide information, and control smart home devices.
Text generation and content creation
- Creative writing: LLMs can generate different text forms, including poems, scripts, marketing copy, and news articles.
- Translation: They accurately translate between languages, breaking down communication barriers.
- Summarization: LLMs can condense lengthy documents, articles, or meeting transcripts into key points.
Research and development
- Scientific discovery: LLMs can analyze vast amounts of scientific data, helping researchers find patterns, make predictions, and accelerate discoveries in medicine, biology, and other fields.
- Sentiment analysis: LLMs can measure the overall emotion or sentiment behind customer reviews, social media posts, or surveys, providing valuable insights into customer sentiment.
Coding and software development
- Code generation: LLMs can write code based on natural language descriptions, assisting developers and making programming more accessible.
- Code debugging: They can detect errors within code and suggest solutions, helping developers find bugs faster.
Other applications
- Education: LLMs can personalize learning experiences, provide adaptive tutoring, and generate practice materials.
- Finance: LLMs can analyze financial reports, news feeds, and market data to predict stock prices or generate investment summaries.
- Legal: LLMs can review contracts, draft legal documents, and help lawyers with research.
The applications of LLMs are constantly expanding and evolving. We can expect even more creative and innovative use cases to emerge as technology advances.
What are the advantages of LLMs?
LLMs offer a wide range of advantages to organizations and users, making them a valuable tool for various applications:
- Extensibility and adaptability: LLMs can be a versatile foundation for creating customized models tailored to specific use cases. Organizations can develop models that cater to their unique needs and requirements by fine-tuning an LLM with additional training data.
- Flexibility: A single LLM can be utilized for various tasks and deployments across different organizations, users, and applications. This flexibility allows for efficient resource allocation and reduces the need to develop multiple specialized models.
- High performance: Modern LLMs are designed to deliver high-performance results, with the ability to generate rapid, low-latency responses. This makes them suitable for real-time applications and scenarios where quick processing is essential.
- Increasing accuracy: As the number of parameters and the volume of training data grows, LLMs using the transformer architecture can achieve higher levels of accuracy. This improvement in accuracy enables LLMs to tackle more complex tasks and deliver more reliable results.
- Streamlined training process: Many LLMs are trained on unlabeled data, simplifying and accelerating the training process. This approach reduces the need for manual data labeling, saving time and resources during model development.
- Enhanced efficiency: By automating routine tasks, LLMs can significantly save employees’ time and effort. This increased efficiency allows organizations to allocate human resources to more critical and strategic tasks, improving overall productivity.
What are the limitations of LLMs?
While LLMs offer numerous benefits, they also present several challenges and limitations that must be carefully considered:
- High development costs: Training LLMs requires vast amounts of expensive graphics processing unit (GPU) hardware and enormous datasets, leading to substantial development costs.
- Costly operations: Even after the initial training and development phase, the ongoing operational costs for organizations hosting LLMs can be extremely high.
- Potential for bias: LLMs are often trained on unlabeled data. There is a risk of bias being introduced into the models, as it can be challenging to ensure that all known biases have been effectively removed.
- Ethical concerns: LLMs can raise issues related to data privacy and may generate harmful or inappropriate content if not properly controlled.
- Lack of explainability: Users may find it challenging to understand how an LLM arrived at a particular output, as the reasoning behind the generated results is not always transparent or easily explainable.
- Hallucination: LLMs can sometimes provide inaccurate or nonsensical responses that are not based on the data they were trained on, a phenomenon known as AI hallucination.
- Complexity of troubleshooting: Modern LLMs are incredibly complex technologies with billions of parameters, making troubleshooting difficult and time-consuming.
- Glitch tokens: Since 2022, there has been a growing trend of maliciously designed prompts, known as glitch tokens, which can cause LLMs to malfunction or produce undesired outputs.
- Security risks: Malicious actors can exploit LLMs to create more sophisticated and convincing phishing attacks targeting employees, posing significant security risks to organizations.

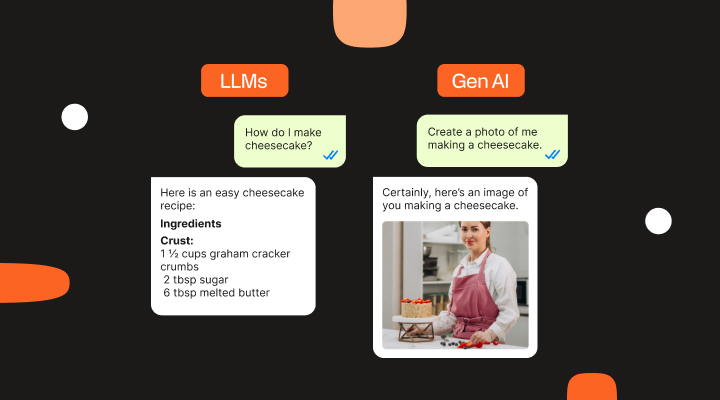
What is the difference between LLMs and generative AI?
While large language models serve as the backbone for advanced applications in text generation, understanding, and processing, GenAI is a broader term that includes various artificial intelligence tools, such as AI chatbots and virtual assistants. LLMs can be considered a subset of GenAI technologies, focused specifically on advanced language understanding and generation.
What is the future of large language models?
The future of LLMs holds immense promise, with continuous advancements pushing the boundaries of what these neural networks can achieve. As businesses increasingly integrate LLMs into their processes, we expect further efficiency, personalization, and improvements in customer satisfaction.
FAQs
Unsupervised learning is how LLMs initially learn language structure by analyzing massive, unlabeled datasets. Fine-tuning is like specialized training for specific tasks (translation, writing, etc.) using smaller, labeled data.
Read more about unsupervised and fine-tuning here:


