






How MCP helps platforms reduce integration overhead
Most platforms don’t slow down because of product ideas. They slow down because engineering time gets eaten by the operational glue around integrations. MCP changes where that work lives.

Most communication platform teams do not slow down because they run out of ideas. They slow down because engineering time gets swallowed by the invisible layer underneath the product: provisioning workflows, admin tooling, webhook routing, approval tracking, and status monitoring. None of that is what customers pay for, but it still has to be built, maintained, and updated as you scale across channels, countries, and tenants.
The integration overhead problem
When you integrate a CPaaS provider for messaging, you are solving for message delivery. SMS, WhatsApp, RCS, email, those messages reach customers reliably through carrier connections you would never build yourself. That part works.
What many platform teams discover after integration is the hidden cost. You also end up building and maintaining operational infrastructure around those APIs: provisioning workflows, admin portals, webhook routing, status tracking, and multi-tenant isolation.
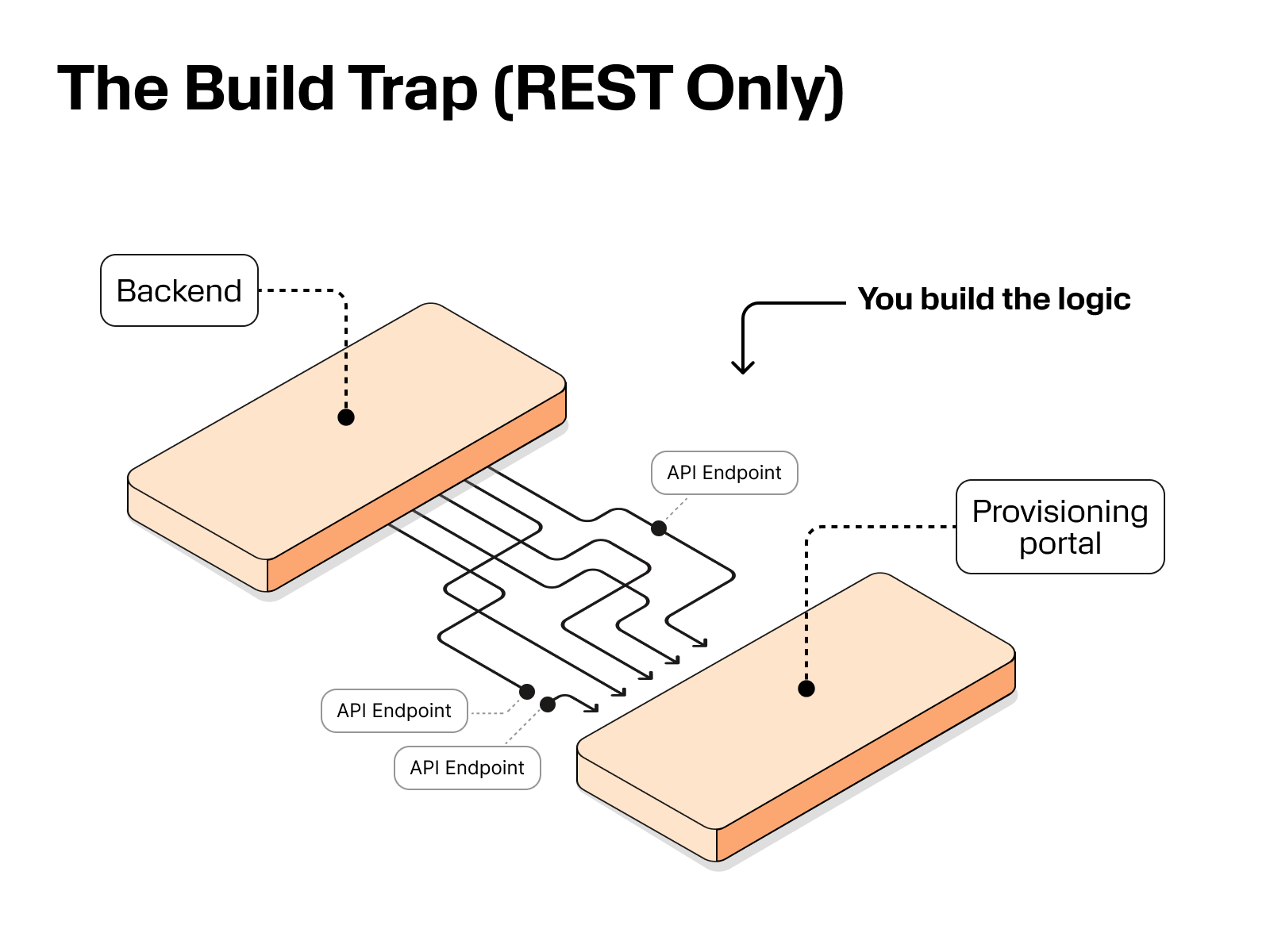
This is integration overhead: all the extra operational work you have to build around REST APIs because they give you individual building blocks, not ready-to-run workflows. Building those blocks into complete workflows takes real engineering time, and it keeps growing as you scale.
And your competitive differentiation is not in provisioning WhatsApp accounts or registering sender IDs. It is in campaign personalization, audience segmentation, and journey orchestration, the experiences your customers actually pay for.
Where engineering capacity goes
In many platform teams, the split ends up looking like this:
40 to 50%
customer-facing features
10 to 20%
maintaining existing APIs
30 to 40%
operational infrastructure
The rest goes to day to day operations
That last bucket is the one that matters. It is where you build smarter segmentation, better orchestration, and more personalized customer experiences. But it is often the smallest slice, because operational work expands to fill the available capacity.
For years, this was simply the cost of doing business. REST APIs were the only realistic option. You either built your own messaging infrastructure, which is prohibitively expensive, or integrated via APIs and accepted the operational overhead.
Then a third option emerged.
What is Model Context Protocol (MCP)?
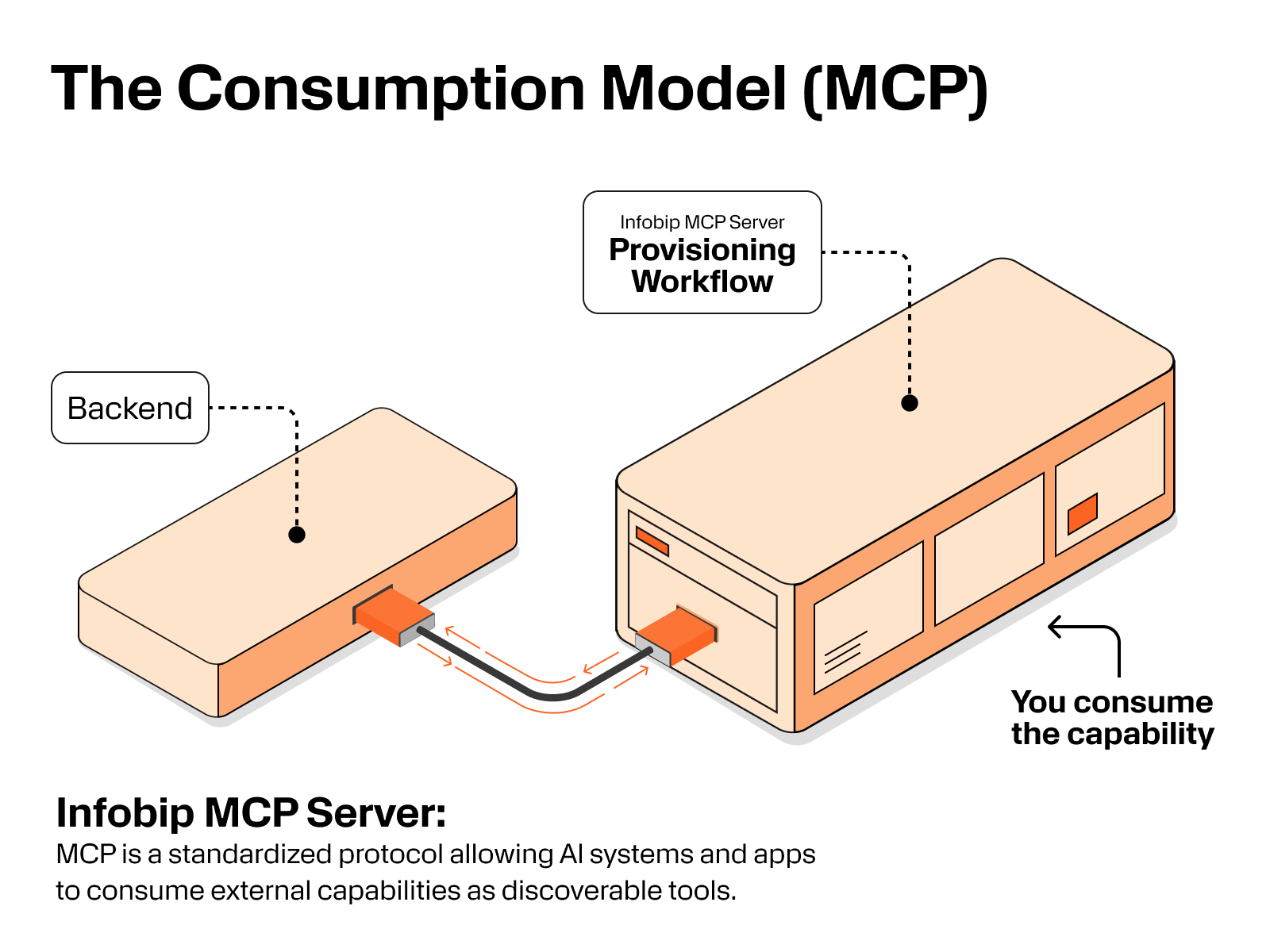
Model Context Protocol (MCP) is a standardized protocol that lets AI systems and applications communicate with external services through a standardized interface. Instead of spending time on custom integrations, MCP allows providers to expose capabilities as discoverable tools that an application or agent can invoke directly.
The simplest way to think about it is this: REST APIs give you endpoints, MCP gives you workflows. With REST, you write code to stitch systems together and orchestrate multi-step operations. With MCP, you consume operational capabilities as managed workflows, without building the orchestration layer yourself.
How MCP works
At its core, MCP uses a client-server model. Your application connects to an MCP server that exposes operational capabilities, then invokes the right workflow when needed. The key shift is where orchestration happens. With REST APIs, orchestration lives in your platform. With MCP, the provider can handle the multi-step operational logic behind the scenes and return a structured status and result.
The solution: a dual protocol architecture
MCP is not designed to replace REST APIs. The best platform architectures use both.
- Use REST APIs for real-time operations on the critical path: sending messages, receiving webhooks, and querying high-throughput data.
- Use MCP for operational workflows that happen occasionally and require orchestration: provisioning accounts, registering sender IDs, configuring tenants, setting up webhooks, and operational analysis.
A simple rule of thumb:
- REST handles real-time value delivery
- MCP handles operational overhead
This keeps the fast path fast, while reducing the operational drag that builds up over time.

Use cases: MCP consumption patterns
Instead of looking at MCP as a long list of use cases, it is more helpful to look at it as an operating model. In practice, MCP shows up in three patterns, and most platforms use a mix depending on how mature their automation is.
Pattern 1: Human-in-the-loop agentic ops
This is where operations teams use AI agents to discover and invoke MCP tools using natural language. Instead of writing scripts or jumping between admin consoles, someone can describe what they need in plain language, for example: “Set up Acme Corp for WhatsApp in Germany and France, and register SMS sender IDs for both countries.”
From there, the agent interprets the request, finds the relevant tools, runs them in the right order, monitors progress, and flags anything that needs human review. This is especially useful when workflows are complex, not fully standardized, or involve judgment calls.
Best for: More complex or infrequent operations, situations where the exact steps are not always the same, and teams where not everyone wants to work directly with APIs.
Pattern 2: Self-serve provisioning flows
In this pattern, your customers trigger provisioning directly through your platform UI. The flow is simple: your frontend collects what’s needed (business details, countries, channels, use case), and your backend translates that input into a single MCP tool call. You then display progress and status back to the customer, and notify them when everything is ready.
The big difference compared to a traditional REST integration is that your backend is not orchestrating a chain of API calls with custom error handling, retries, and status tracking. It’s invoking one capability and letting the MCP server manage the workflow.
Best for: High-volume self-service features, predictable provisioning workflows, and improving time-to-value for customers.
Pattern 3: Event-driven automation
This is the most automated model. Here, business events trigger MCP workflows without anyone needing to kick things off manually. For example, when a signed contract comes in, your platform can extract the requirements, invoke MCP tools for the right channels in parallel, track approval status, and notify sales or customer success once everything is ready.
The real value is that onboarding shifts from manual coordination to a repeatable workflow. Instant-approval operations can complete in minutes, and approval-based workflows become trackable and far less painful to manage.
Best for: Onboarding at scale, automation and reducing operational bottlenecks across teams.
Impact: what this unlocks
The real value of MCP is not just speed. It is focus.
When operational workflows are consumed instead of built, engineering teams spend less time maintaining provisioning logic and internal tooling. That capacity shifts toward customer-facing product work: personalization, segmentation, orchestration, and analytics that create real differentiation.
In other words, MCP helps platforms protect the part of the roadmap that actually drives growth.
When MCP makes sense
MCP is most valuable when operational workflows are a real part of your day-to-day, not an occasional task. In practice, it tends to work best when you have:
- A multi-tenant SaaS platform managing hundreds or thousands of customers
- High operational complexity across multiple channels and countries
- Frequent provisioning and configuration work (weekly or daily, not quarterly)
- Engineering capacity constraints are mostly locked into building operational infrastructure, instead of customer-facing functionalities
- Growth ambitions where manual processes become bottlenecks
It can be overkill if your setup is relatively simple, for example:
- A small customer base (around 10 to 20 customers)
- Single-channel, single-country operations
- Infrequent provisioning needs
- Enough engineering capacity to comfortably build and maintain custom workflows
A few practical considerations
- AI orchestration costs: The human-in-the-loop pattern can introduce LLM usage costs, but for most teams these are small compared to the engineering time saved.
- Ecosystem maturity: MCP is still early, but the protocol and capabilities are still largely evolving, same as most of the fundamental pieces of the AI ecosystem, however the pace is moving extremely fast.
From building to consuming
For years, integrating CPaaS meant choosing between building your own messaging infrastructure, which is unrealistic for most teams, or integrating via REST APIs and taking on the operational work that comes with it.
MCP introduces a third path: consume operational capabilities as workflows. REST still powers real-time delivery where latencies and throughput matter. MCP covers the operational side, the multi-step setup and configuration work that tends to absorb engineering time without improving your product.
That shift protects feature velocity. Instead of spending cycles building and maintaining internal provisioning and admin infrastructure, teams can focus on the experiences that actually differentiate their platform.
Final thoughts
It’s worth being clear about what MCP is all about. It is not replacing CPaaS or REST APIs. Message delivery still runs on the same underlying infrastructure, and REST remains the best option for real-time operations like sending messages and receiving webhooks. What MCP changes is the operational layer around that delivery, the multi-step setup, provisioning, configuration, and monitoring work that tends to consume engineering capacity without making your platform more valuable to customers.
Even so, most CPaaS integrations today still rely on REST alone, which means many teams are still rebuilding the same operational workflows and internal tooling from scratch.
That gap creates an opportunity.
Platforms that start consuming operational capabilities can free up significant engineering capacity and reduce onboarding friction. Instead of spending cycles maintaining provisioning workflows and admin infrastructure, teams can redirect that effort into the roadmap that actually drives growth, things like journey orchestration, audience intelligence, and AI-powered segmentation.
So the question is no longer just “should we build or buy?”
It becomes: should we keep building operational infrastructure, or should we consume it as a capability?
Ready to reduce integration overhead?
Explore Infobip’s MCP server capabilities or speak with our integration team about implementing a dual protocol architecture.
