






Blog
Explore a wide range of topics, get inspired by the latest trends, and learn how to create conversational experiences that make an impact on your bottom line.
Messaging Trends 2026
Discover the current trends in business communication based on 628 billion mobile channel interactions that took place on our platform in 2025 and a review of the 3.8 trillion messages exchanged over the past 20 years.

Posted onJune 26, 2026.
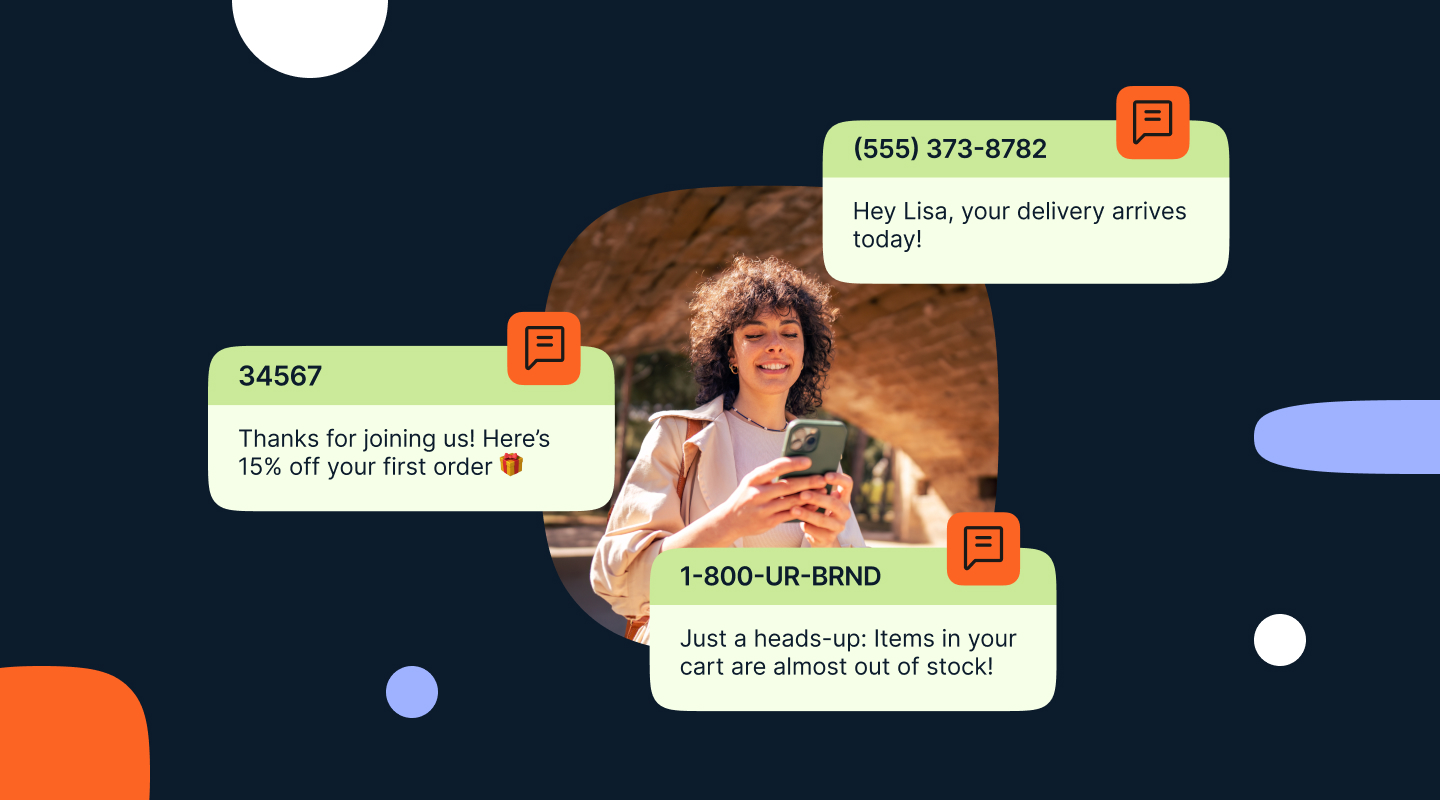
10DLC vs short code vs toll-free: How to choose the right number.
Learn the key differences between 10DLC, short code, and toll-free numbers for SMS campaigns and discover which option is best for you.

Posted onJune 25, 2026.
Omnichannel customer data: The complete guide to unified profiles and real-time activation .
Unify omnichannel customer data, including conversational signals, into real-time profiles. Activate across 15+ messaging channels with Infobip AgentOS.

Posted onJune 24, 2026.
How to create an AI.
Many people use the term AI without truly understanding what it means and where it sits in the hierarchy of data science and machine learning. In this blog we explain the theory and what it takes to build real artificial intelligence with practical applications.

Posted onJune 18, 2026.
SMS marketing benchmarks: Key stats by industry.
Find out how your SMS marketing ranks against the averages for your industry and how you can move the needle to achieve better results.

Posted onJune 11, 2026.
What are flash calls and are they a valid verification method?.
Flash calls offer a cost-effective and theoretically low-friction method of authenticating mobile numbers, but there is more than one catch. Here we discuss how they work and compare them directly with A2P SMS as a verification method.

Posted onJune 10, 2026.
Branded text messaging: Sender IDs & RCS profiles.
Learn how branded SMS and RCS Business Profiles display your company name instead of a number, and why it matters for open rates and trust.

Posted onJune 10, 2026.
Maybank Philippines: Powering consistent, customer-centric banking across channels .
Learn how Maybank Philippines is building a future-ready omnichannel strategy in a mobile-first market to deliver fast, simple, and secure experiences.

Posted onJune 9, 2026.
What is branded calling? Branded Calling ID explained .
Discover branded calling ID and how it can boost answer rates and trust in the face of fraud attacks while increasing your brand’s cost savings.

Posted onJune 2, 2026.
Benefits of chatbots for business and customers: The complete guide.
Discover the real benefits of chatbots built on an enterprise platform: 24/7 omnichannel support, 60% cost reduction, CDP-powered personalization, and AI agent escalation. With customer results, industry examples, and a full FAQ.

Posted onJune 2, 2026.
Customer retention strategies 2025: 20+ ways to grow customer lifetime value.
Customer retention strategies that actually work. 21 tactics covering onboarding, personalization, loyalty programs, win-back campaigns, and churn prevention.

Posted onJune 1, 2026.
Gibberlink: AI’s secret language explained (2026 update).
Learn how Gibberlink works, where it fits in the 2026 AI agent protocol stack, and what it means for enterprises building agentic workflows.

Posted onJune 1, 2026.
eSIM vs SIM card: Differences, pros and cons.
What is an eSIM, how is it different than a standard SIM, and what are the pros and cons? Learn this and much more!
Posted on{{date_formatted}}.
{{title}}.
{{excerpt}}
Tags:- {{term.name}}.